Trie/字典树/前缀树原理及可视化
一句话总结
Trie 树就是多叉树结构 的延伸,是一种针对字符串进行特殊优化的数据结构。
Trie 树在处理字符串相关操作时有诸多优势,比如节省公共字符串前缀的内存空间、方便处理前缀操作、支持通配符匹配等。
本文仅是 Trie 树(也叫做字典树、前缀树)的原理介绍, 动手实现 TrieMap/TrieSet 我放到了二叉树系列习题章节 后面的数据结构设计章节。理由和上篇 TreeMap/TreeSet 原理 相同,在基础知识章节我不准备讲解这种复杂结构的具体实现,初学者也没必要在这个阶段理解 Trie 树的代码实现。
但是我依然把 Trie 树的原理讲解放在这里,有两个目的:
1、让你直观地感受到二叉树结构的种种幻化,你也许能理解我的教程特别强调二叉树结构的原因了。
2、在开头让你知道有这么一种数据结构,了解它的 API 以及适用的场景。未来你遇到相关的问题,也许就能想到用 Trie 树来解决,最起码有个思路,大不了回来复制代码模板嘛。这种数据结构的实现都是固定的,笔试面试也不会让你从头手搓 Trie 树,复制粘贴直接拿去用就可以了。
好了,废话不多说,让我们开始吧。
本站将会带你实现一个 TrieMap 和 TrieSet,先来梳理一下我们已经实现过的 Map/Set 类型:
-
标准的 哈希表 HashMap,底层借助一个哈希函数把键值对存在 table 数组中,有两种解决哈希冲突的方法。它的特点是快,即基本的增删查改操作时间复杂度都是 O(1)。哈希集合 HashSet 是 HashMap 的简单封装。
-
哈希链表 LinkedHashMap,是双链表结构 对标准哈希表的加强。它继承了哈希表的操作复杂度,并且可以让哈希表中的所有键保持「插入顺序」。LinkedHashSet 是 LinkedHashMap 的简单封装。
-
哈希数组 ArrayHashMap,是数组结构 对标准哈希表的加强。它继承了哈希表的操作复杂度,并且提供了一个额外的 randomKey 函数,可以在 O(1) 的时间返回一个随机键。ArrayHashSet 是 ArrayHashMap 的简单封装。
-
TreeMap 映射,底层是一棵二叉搜索树(编程语言标准库一般使用经过改良的自平衡红黑树),基本增删查改操作复杂度是 O(logN),它的特点是可以动态维护键值对的大小关系,有很多额外的 API 操作键值对。TreeSet 集合是 TreeMap 映射的简单封装。
TrieSet 也是 TrieMap 的简单封装,所以下面我们聚焦 TrieMap 的实现原理即可。
Trie 树的主要应用场景
Trie 树是一种针对字符串有特殊优化的数据结构,这也许它又被叫做字典树的原因。Trie 树针对字符串的处理有若干优势,下面一一列举。
节约存储空间
用 HashMap 对比吧,比如说这样存储几个键值对:
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("app", 2);
map.put("appl", 3);
回想哈希表的实现原理,键值对会被存到 table 数组中,也就是说它真的创建 "apple"、"app"、"appl" 这三个字符串,占用了 12 个字符的内存空间。
但是注意,这三个字符串拥有共同的前缀,"app" 这个前缀被重复存储了三次,"l" 也被重复存储了两次。
如果换成 TrieMap 来存储:
// Trie 树的键类型固定为 String 类型,值类型可以是泛型
TrieMap<Integer> map = new TrieMap<>();
map.put("apple", 1);
map.put("app", 2);
map.put("appl", 3);
Trie 树底层并不会重复存储公共前缀,所以只需要 "apple" 这 5 个字符的内存空间来存储键。
这个例子数据量很小,你感觉重复存储几次没啥大不了,但如果键非常多、非常长,且存在大量公共前缀(现实中确实经常有这种情况,比如证件号),那么 Trie 树就能节约大量的内存空间。
方便处理前缀操作
举个例子就明白了:
// Trie 树的键类型固定为 String 类型,值类型可以是泛型
TrieMap<Integer> map = new TrieMap<>();
map.put("that", 1);
map.put("the", 2);
map.put("them", 3);
map.put("apple", 4);
// "the" 是 "themxyz" 的最短前缀
System.out.println(map.shortestPrefixOf("themxyz")); // "the"
// "them" 是 "themxyz" 的最长前缀
System.out.println(map.longestPrefixOf("themxyz")); // "them"
// "tha" 是 "that" 的前缀
System.out.println(map.hasKeyWithPrefix("tha")); // true
// 没有以 "thz" 为前缀的键
System.out.println(map.hasKeyWithPrefix("thz")); // false
// "that", "the", "them" 都是 "th" 的前缀
System.out.println(map.keysWithPrefix("th")); // ["that", "the", "them"]
除了 keysWithPrefix 方法的复杂度取决于返回结果的长度,其他前缀操作的复杂度都是 O(L),其中 L 是前缀字符串长度。
你想想上面这几个操作,用 HashMap 或者 TreeMap 能做到吗?应该只能强行遍历所有键,然后一个个比较字符串前缀,复杂度非常高。
话说,这个 keysWithPrefix 方法,是不是很适合做自动补全功能呢?
可以使用通配符
还是举个例子:
// Trie 树的键类型固定为 String 类型,值类型可以是泛型
// 支持通配符匹配,"." 可以匹配任意一个字符
TrieMap<Integer> map = new TrieMap<>();
map.put("that", 1);
map.put("the", 2);
map.put("team", 3);
map.put("zip", 4);
// 匹配 "t.a." 的键有 "team", "that"
System.out.println(map.keysWithPattern("t.a.")); // ["team", "that"]
// 匹配 ".ip" 的键有 "zip"
System.out.println(map.hasKeyWithPattern(".ip")); // true
// 没有匹配 "z.o" 的键
System.out.println(map.hasKeyWithPattern("z.o")); // false
通配符匹配,是不是可以做搜索引擎的关键词匹配呢?这个功能用 HashMap 或者 TreeMap 肯定是做不到的。
可以按照字典序遍历键
举例说明:
// Trie 树的键类型固定为 String 类型,值类型可以是泛型
TrieMap<Integer> map = new TrieMap<>();
map.put("that", 1);
map.put("the", 2);
map.put("them", 3);
map.put("zip", 4);
map.put("apple", 5);
// 按照字典序遍历键
System.out.println(map.keys()); // ["apple", "that", "the", "them", "zip"]
这个功能 TreeMap 也能做到,算是和 Trie 树打了个平手,但是 HashMap 就做不到了。
上面介绍了 Trie 树的特色功能,下面我们来看看它的实现原理。
Trie 树的基本结构
Trie 树本质上就是一棵从二叉树衍生出来的多叉树。
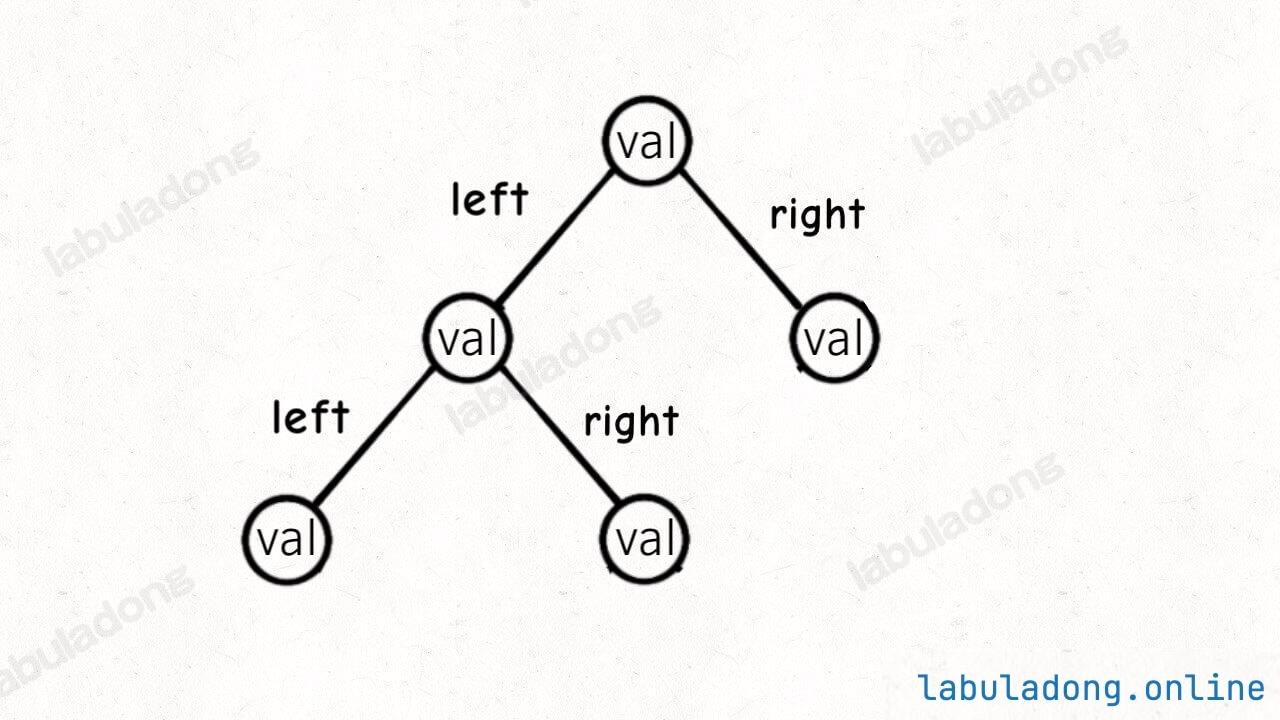
二叉树节点的代码实现是这样:
// 基本的二叉树节点
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
// 基本的二叉树节点
class TreeNode {
int val;
TreeNode left, right;
}
其中 left, right 存储左右子节点的指针,所以二叉树的结构是这样:
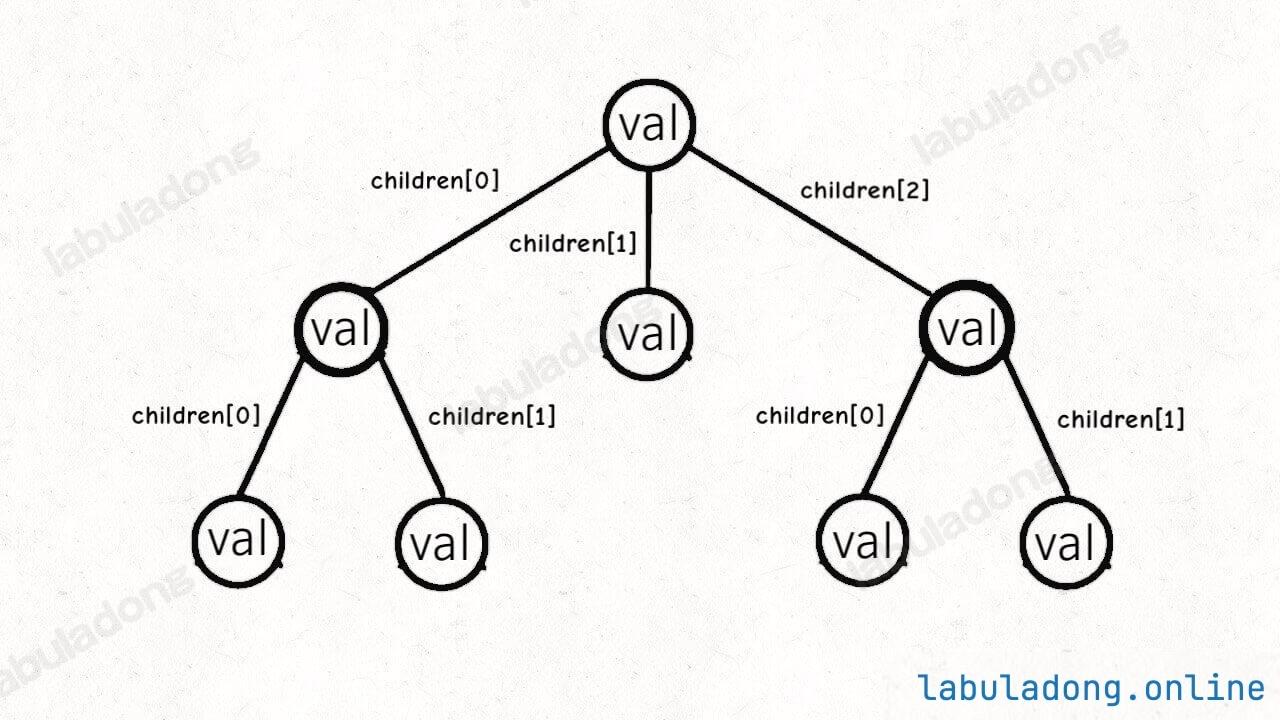
多叉树节点的代码实现是这样:
// 基本的多叉树节点
type TreeNode struct {
val int
children []*TreeNode
}
// 基本的多叉树节点
class TreeNode {
int val;
TreeNode[] children;
}
其中 children 数组中存储指向孩子节点的指针,所以多叉树的结构是这样:
而 TrieMap 中的树节点 TrieNode 的代码实现是这样:
// Trie 树节点实现
type TrieNode struct {
val interface{}
children [256]*TrieNode
}
// Trie 树节点实现
class TrieNode<V> {
V val = null;
TrieNode<V>[] children = new TrieNode[256];
}
这个 val 字段存储键对应的值,children 数组存储指向子节点的指针。
但是和之前的普通多叉树节点不同,TrieNode 中 children 数组的索引是有意义的,代表键中的一个字符。
比如说 children[97] 如果非空,说明这里存储了一个字符 'a',因为 'a' 的 ASCII 码为 97。
我们的模板只考虑处理 ASCII 字符,所以 children 数组的大小设置为 256。不过这个可以根据具体问题修改。
比如在实际做题时,题目说了只包含字符 a-z,那么你可以把大小改成 26;或者你不想用字符索引来映射,直接用哈希表 HashMap<Character, TrieNode> 也可以,都是一样的效果。
有了以上铺垫,Trie 树的结构是这样的:
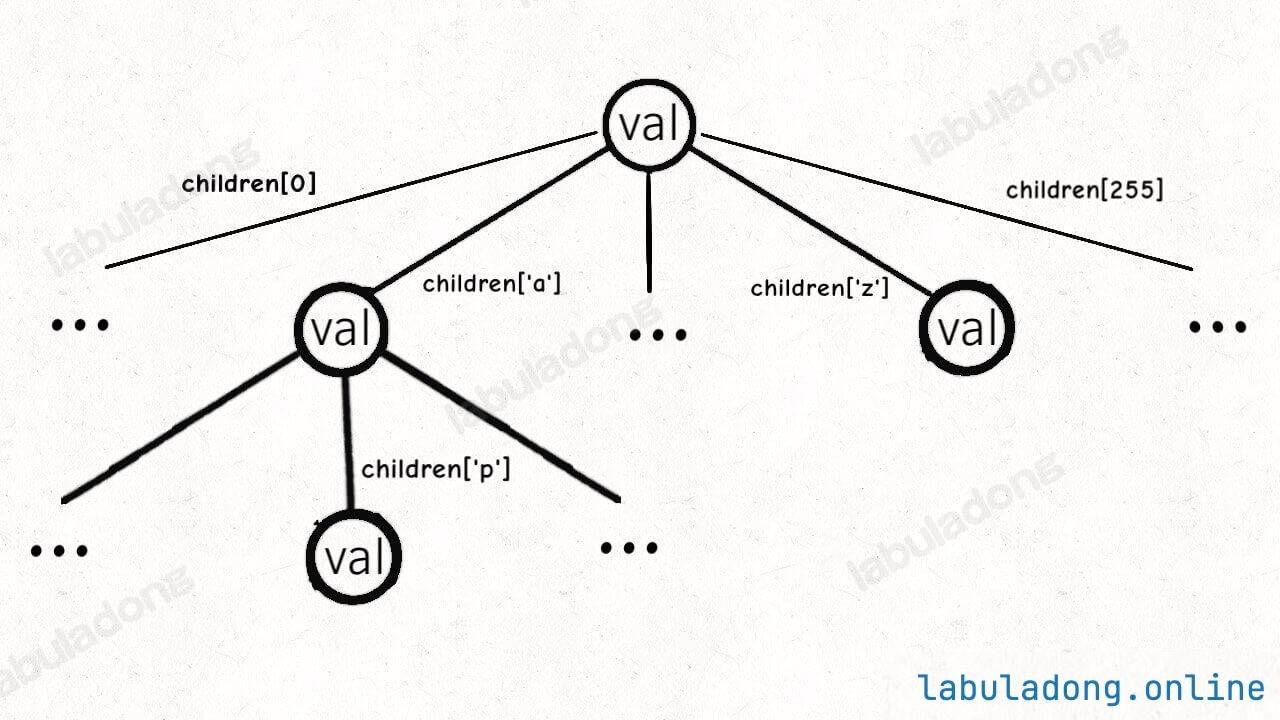
一个节点有 256 个子节点指针,但大多数时候都是空的,可以省略掉不画,所以一般你看到的 Trie 树长这样:
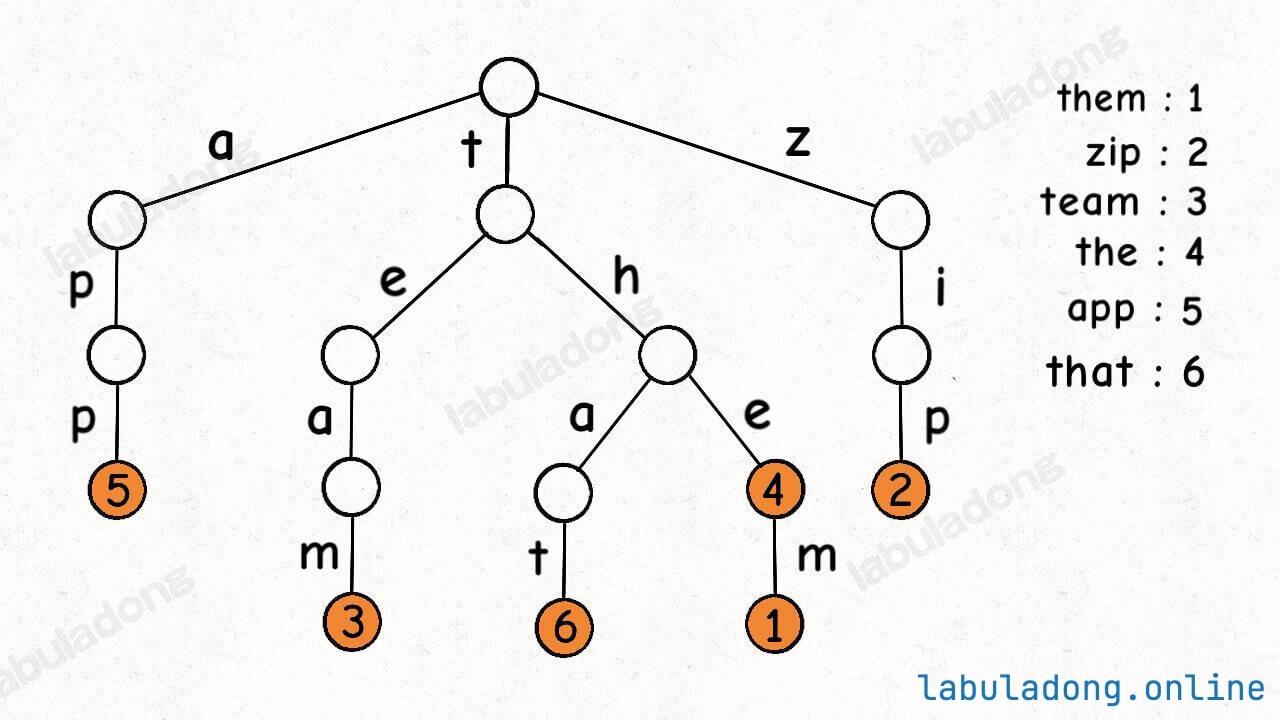
这是在 TrieMap<Integer> 中插入一些键值对后的样子,白色节点代表 val 字段为空,橙色节点代表 val 字段非空。
这里要特别注意,TrieNode 节点本身只存储 val 字段,并没有一个字段来存储字符,字符是通过子节点在父节点的 children 数组中的索引确定的。
形象理解就是,Trie 树用「树枝」存储字符串(键),用「节点」存储字符串(键)对应的数据(值)。所以我在图中把字符标在树枝,键对应的值 val 标在节点上:
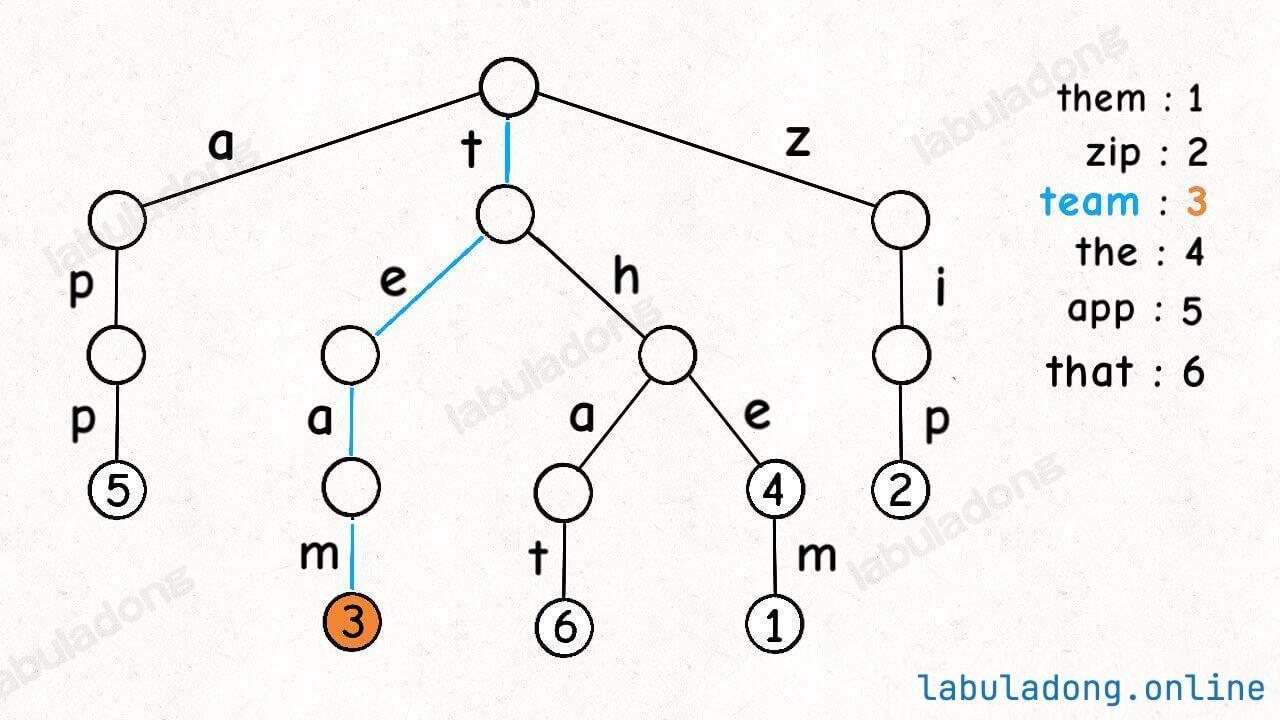
现在你应该知道为啥 Trie 树也叫前缀树了,因为其中的字符串共享前缀,相同前缀的字符串集中在 Trie 树中的一个子树上,给字符串的处理带来很大的便利。
TrieMap API
我们看一下 TrieMap 的 API,为了举例 API 的功能,假设 TrieMap 中已经存储了如下键值对:
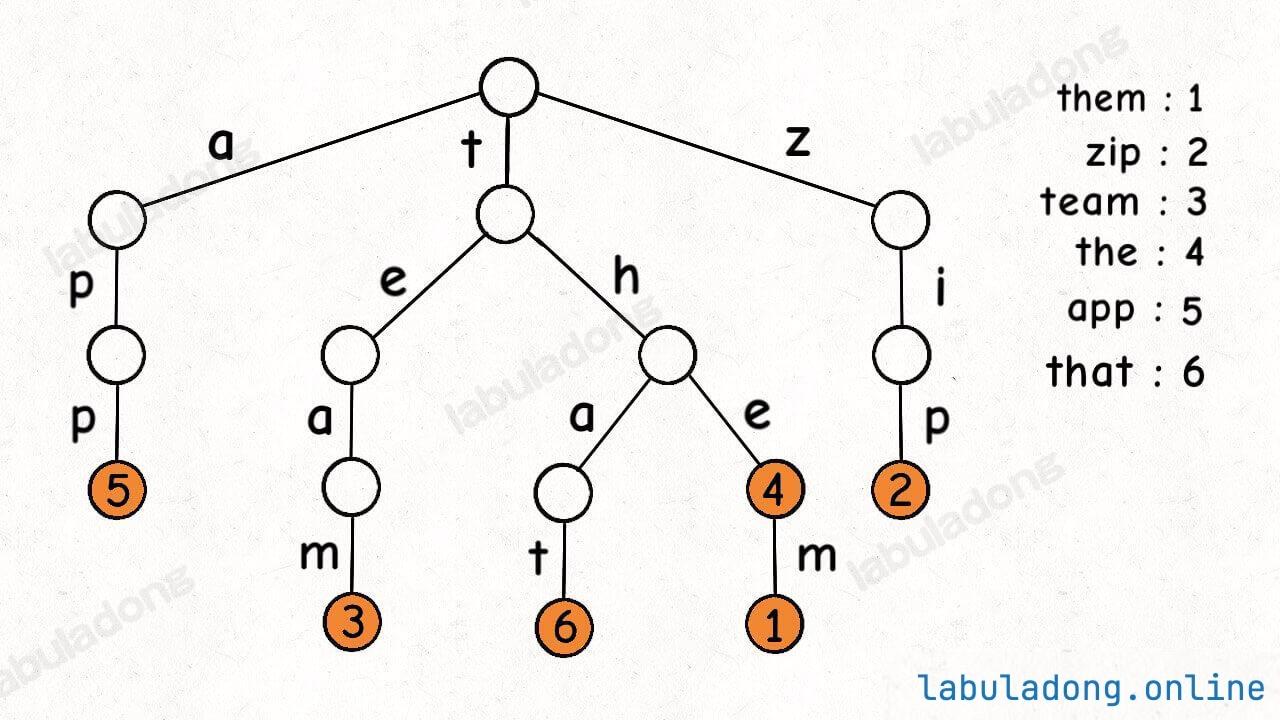
// 底层用 Trie 树实现的键值映射
// 键为 string 类型,值为类型 V
type TrieMap struct{}
// 在 Map 中添加 key
func (tm *TrieMap) put(key string, val interface{})
// 删除键 key 以及对应的值
func (tm *TrieMap) remove(key string)
// 搜索 key 对应的值,不存在则返回 nil
// get("the") -> 4
// get("tha") -> nil
func (tm *TrieMap) get(key string) interface{}
// 判断 key 是否存在在 Map 中
// containsKey("tea") -> false
// containsKey("team") -> true
func (tm *TrieMap) containsKey(key string) bool
// 在 Map 的所有键中搜索 query 的最短前缀
// shortestPrefixOf("themxyz") -> "the"
func (tm *TrieMap) shortestPrefixOf(query string) string
// 在 Map 的所有键中搜索 query 的最长前缀
// longestPrefixOf("themxyz") -> "them"
func (tm *TrieMap) longestPrefixOf(query string) string
// 搜索所有前缀为 prefix 的键
// keysWithPrefix("th") -> ["that", "the", "them"]
func (tm *TrieMap) keysWithPrefix(prefix string) []string
// 判断是和否存在前缀为 prefix 的键
// hasKeyWithPrefix("tha") -> true
// hasKeyWithPrefix("apple") -> false
func (tm *TrieMap) hasKeyWithPrefix(prefix string) bool
// 通配符 . 匹配任意字符,搜索所有匹配的键
// keysWithPattern("t.a.") -> ["team", "that"]
func (tm *TrieMap) keysWithPattern(pattern string) []string
// 通配符 . 匹配任意字符,判断是否存在匹配的键
// hasKeyWithPattern(".ip") -> true
// hasKeyWithPattern(".i") -> false
func (tm *TrieMap) hasKeyWithPattern(pattern string) bool
// 返回 Map 中键值对的数量
func (tm *TrieMap) size() int
// 底层用 Trie 树实现的键值映射
// 键为 String 类型,值为类型 V
class TrieMap<V> {
// **** 增/改 ****
// 在 Map 中添加 key
public void put(String key, V val);
// **** 删 ****
// 删除键 key 以及对应的值
public void remove(String key);
// **** 查 ****
// 搜索 key 对应的值,不存在则返回 null
// get("the") -> 4
// get("tha") -> null
public V get(String key);
// 判断 key 是否存在在 Map 中
// containsKey("tea") -> false
// containsKey("team") -> true
public boolean containsKey(String key);
// 在 Map 的所有键中搜索 query 的最短前缀
// shortestPrefixOf("themxyz") -> "the"
public String shortestPrefixOf(String query);
// 在 Map 的所有键中搜索 query 的最长前缀
// longestPrefixOf("themxyz") -> "them"
public String longestPrefixOf(String query);
// 搜索所有前缀为 prefix 的键
// keysWithPrefix("th") -> ["that", "the", "them"]
public List<String> keysWithPrefix(String prefix);
// 判断是和否存在前缀为 prefix 的键
// hasKeyWithPrefix("tha") -> true
// hasKeyWithPrefix("apple") -> false
public boolean hasKeyWithPrefix(String prefix);
// 通配符 . 匹配任意字符,搜索所有匹配的键
// keysWithPattern("t.a.") -> ["team", "that"]
public List<String> keysWithPattern(String pattern);
// 通配符 . 匹配任意字符,判断是否存在匹配的键
// hasKeyWithPattern(".ip") -> true
// hasKeyWithPattern(".i") -> false
public boolean hasKeyWithPattern(String pattern);
// 返回 Map 中键值对的数量
public int size();
}